在注塑齒輪生產過程中,由于溫度、注塑時間等因素影響,齒輪可能出現表面黑點、輪齒變形、輪齒缺失等缺陷。由于齒輪缺陷檢測過程往往十分復雜,檢測設備也較為昂貴,因此在實際生產中迫切需要對齒輪進行快速檢測和分析。傳統齒輪制造過程中的檢測方式以人工檢測為主,但是人工檢測不可避免地會出現錯檢、漏檢等問題。機器視覺檢測是一種非接觸式無損檢測,在高速、精細和重復的制造過程中更加可靠,與傳統的檢測方法相比,具有不可替代的優越性。
陳碩等提出利用廣泛的 Canny 算子提取出待檢齒輪的輪廓,通過計算機求解出輪廓之間的距離,但該方法可能在提取輪廓時出現誤差且識別速度較低。郭冕等提出以模態分解模型將齒輪信號分解,并通過 BP 神經網絡,實現微型塑料齒輪缺陷檢測,但該方法在齒輪信號除噪聲方面檢測識別精度低、魯棒性差。楊亞等采用 SURF 算法對于齒輪的特征進行匹配,獲取缺陷信息后采用 OSTU 算法對缺陷進行分割處理并分類,但是該方法不能很好的分類缺陷。JEON-GHYEON 等采用聲波頻率分析法,采用 CNN 模型進行分析缺陷,數據分析需要大量時間,導致檢測效率降低。仇嬌慧等提出一種改進的 YOLOv5 網絡模型,但該模型中的主干網絡 C3 結構以及添加的注意力機制結構導致參數量上升、識別速度降低。
基于上述問題,本文提出一種改進的 YOLOv5s (即 VSD-YOLOv5s) 網絡模型。該網絡模型使用輕量化 ShuffleNetv2 主干網絡,引入 SE 注意力機制及 DI-OU-NMS 方法,提升注塑齒輪缺陷檢測的識別精度與識別速度。
一、YOLOv5s 網絡模型結構
YOLOv5 包含 4 個版本的目標檢測網絡模型,即 YOLOv5s、YOLOv5m、YOLOv51 和 YOLOv5x,模型的規模和訓練參數的數量在 4 個版本中依次增加,其中,YOLOv5s 網絡模型最快。考慮到缺陷檢測需要嚴格的實時性,本文以最簡單、最快的網絡模型 YOLOv5s 作為基準,來完成表面缺陷的在線檢測。YOLOv5s 的結構由 4 部分組成,輸入端、Backbone 網絡、Neck 網絡、Prediction 輸出端,如圖 1 所示。輸入端采用自適應圖像填充、自適應錨框計算和 Mosaic 數據增強,以提升檢測的準確性; 在 Backbone 網絡中,使用了 Focus 模塊、C3 主干網絡模塊和卷積模塊。Focus 模塊主要用于切片操作,通過增加特征圖的維度來縮小特征圖的尺寸,同時保留圖像特征信息。C3 主干網絡模塊中的殘差結構有效防止梯度消失,使得特征更加細致; Neck 網絡中主要包含 C3 網絡模塊、上采樣和下采樣過程,降低計算量,同時提高特征融合能力和信息保留度。Prediction 輸出端中使用 NMS 后處理方法篩選多個目標錨框,抑制無效信息,以提高識別準確性。

二、改進的 YOLOv5s 網絡模型
為了滿足注塑齒輪表面缺陷在線檢測的速度和識別精度要求,本文提出了一種 VSD-YOLOv5s 網絡模型,對 YOLOv5s 的結構進行了修改,能夠檢測不規則和細小的齒輪缺陷。
將主干網絡 C3 替換為 ShuffleNetV2
YOLOv5s 中主干網絡 C3,如圖 2 所示,旨在更好地提取圖像的深層特征。C3 主要由 Bottleneck、Conv2d、BN + SiLU 激活函數組成,輸入通道分為兩個分支,通過兩個分支的卷積運算,將特征映射中的通道數減半。然后特征映射通過第二分支中的 Conv2d 層、BN 層和瓶頸層,并利用 Concat 層對兩個分支進行深度融合。最后,通過連續穿過 Conv2d 層和 BN 層生成模塊的輸出特征映射,特征映射的大小與主干網絡 C3 的輸入大小相同。
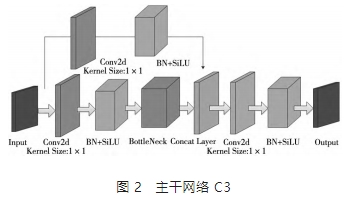
YOLOv5s 主干特征提取網絡采用 C3 網絡結構,帶來較大的參數量,識別速度較慢,應用受限。因此本文將主干特征提取網絡替換為更輕量的 ShuffleNetV2 網絡結構,以實現網絡模型的輕量化,提升識別速度和識別精度。
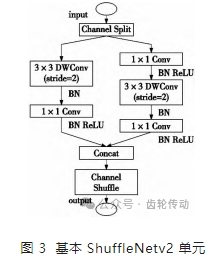
如圖 3 所示,本文使用先進的 ShuffleNetv2 單元,其中 Channel Split 操作將通道數平均分成兩部分,代替了原有的分組卷積結構。每個分支中的卷積層輸入、輸出通道數均相同,其中一個分支不進行任何操作以減少基本單元數。針對 ShuffleNetv2 中單元塊的下采樣,不再采用 Channel Split,通過在每個分支中添加stride = 2 代替原有的 Channel Split 模塊以提高模型容量及檢測效率。最后使用 Concat、Channle Shuffle 代替原有的 Add、Re-LU 模塊以增加模型通道之間的信息交流。綜合上述改動,特征圖空間大小將減半,且使模型具有較高的模型容量和檢測效率,減小了模型的計算復雜度,降低了模型的內存占用率,極大地提高了模型的計算效率。
引入 SE 注意力機制模塊
注意力機制是指重點關注檢測部分而忽略無關要素,SE 注意力機制模塊,如圖 4 所示。首先,對特征映射進行壓縮操作以獲得通道的全局特征; 然后,對全局特征進行激勵操作,以學習通道之間的關系,并獲取不同通道的權重; 最后,對原始特征映射進行乘法操作,得到最終的特征。這個機制有助于模型更加注重信息量最大的通道特征,同時抑制那些不重要的通道特征。
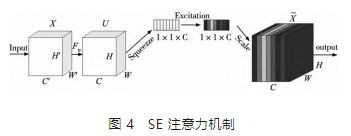
本文通過引入 SE 注意力機制模塊,以建立卷積特征通道之間的相互依賴性來提高網絡的表示能力。首先,輸入特征圖 X,讓其經過 Ftr操作生成特征圖 U; 然后,進行 Squeeze 操作、Excitation 操作,Scale 操作。Squeeze 操作是一種壓縮操作,它將輸入圖像 的高度 H 和寬度 W 都壓縮為 1,但通道數不變的矩陣。通常使用全局平均“池化”操作來實現,以確保最終特征包含輸入圖像的所有信息。Excitation 操作對通過 Squeeze 操作生成的 1 × 1 × C 特征圖進行維度降低和恢復操作,使用全連接層獲取不同通道的權重,自動關注具有最高權重的通道。Scale 操作是一種簡單的加權運算操作,它將 Excitation 操作生成的特征圖與輸入特征圖通過 Sigmoid 激活函數進行 Channel 運算,得到輸出值。
將 NMS 改進為 DIOU-NMS
在 YOLOv5s 原有的 NMS 中,使用 IOU 度量來抑制冗余檢測框,IOU 的全稱為交并比,即表示為預測邊框 A(Prediction box) 和真實邊框 B(Ground truth box) 的交集和并集的比值。IOU 的計算公式為:
但 IOU 度量法并未將兩個框之間的中心點距離考慮在抑制標準之內,此時模型檢測到的遺漏框和錯誤框的數量將會增加。考慮到以上情況,為提高模型檢測的準確性,本文使用 DIOU-NMS 方法,其計算函數方程可以定義為:
式中: Si 表示第 i 個檢測框對應的置信度得分,RDIOU ( M,bi ) 表示基于 DIOU 的檢測框交叉比,M 表示置信度得分最高的檢測框,bi 表示剩余檢測框集合中的第 i 個檢測框,Nt 表示設定的閾值。本文 DIOU 損失函數的懲罰項可以定義為:
如圖 5 所示,c 是覆蓋兩個錨框的最小封閉框的對角線長度,d = ρ 2 ( b,bgt ) 是兩個錨框的中心點的距離。其中 b 和 bgt分別表示和的中心點,ρ 為歐氏距離,c 為覆蓋兩個框的最小包圍框的對角線長度。DIOU 損失函數可以定義為:
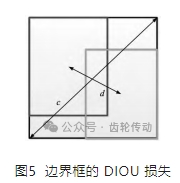
以此來看,DIOU 損失函數不是按外接矩形和并集面積的差值,而是同時最小化外接矩形的面積和兩框中心點的距離,這會使得網絡更傾向于移動邊界框的位置來減少損失函數。因此,考慮到影響邊界框檢測的 3 個幾何因素,即重疊區域、中心點距離和縱橫比,并在此基礎上將 DIOU-NMS 方法添加到本文的模型中,從而加快了模型的收斂速度,提高了模型的性能。
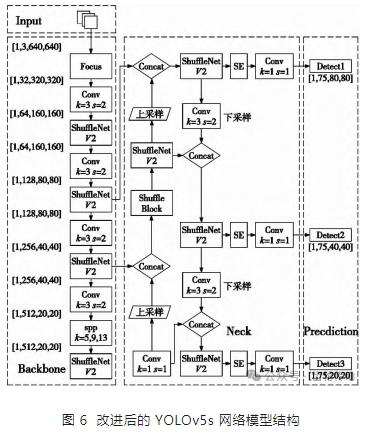
三、結果與分析
實驗環境: 在該實驗中使用的計算機中央處理單元(CPU 型號) 是 Intel(R) Core(TM) i7-12700F CPU@ 2.10 GHz,并且運行存儲器是 16 GB。圖形處理器 (GPU 型號) 為 NVIDIA GeForce RTX 1080 獨立顯卡,顯存為 8 GB。采用 64 位 Windows 10 操作系統作為軟件環境,PyCharm 作為開發平臺,PyTorch 作為深度學習框架,Python 作為編程語言,CUDA 11.3 版本并行計算框架作為開發平臺,如圖 7 所示。

實驗數據集共包含 2000 張分辨率為 640 × 640 的圖片,按照 8∶ 2 的比例劃分為數據集和驗證集。在訓練過程中,設置每批次訓練 16 張圖片,初始學習率為 0.003,IOU 閾值為 0.5,針對所有參照模型均按照這些參數訓練 300 個 Epoch。
數據集預處理: 采用自制的齒輪缺陷數據集,其中主要包括輪齒變形、輪齒缺失、表面黑點3 種情況,如圖 8 所示。運用 VSD-YOLOv5s 模型進行缺陷檢測,采用 Mosaic 增強方法和自適應錨框方法對于數據集進行前期處理。

本文 VSD-YOLOv5s 模型的模型評估指標主要包括準確率(P) 、召回率(R) ,平均識別精度(MAP) 、識別速度(FPS) 。
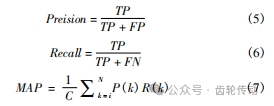
式中: TP 表示正確識別齒輪缺陷,FP 表示對齒輪缺陷識別的錯誤分類,FN 表示不明齒輪缺陷,C 表示齒輪缺陷對象類別的數量,k 表示 IOU 閾值,N 表示閾值的 IOU 數量,P(k) 表示識別精度,R(k) 表示召回率。
如圖 9 所示,為了對 VSD-YOLOv5s 模型的檢測性能進行全面評估,本文采用 YOLOv5s 和 VSD-YOLOv5s 作為縱向比較模型、采用經典的目標檢測模型 Fast- RCNN 作為橫向比較模型,設置相同的實驗參數,上述模型的檢測效果表 1 所示。
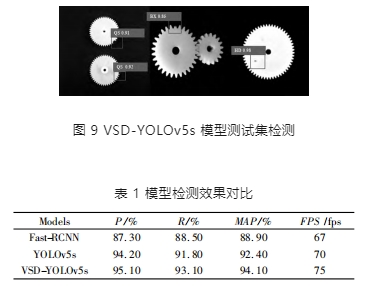
由表1 的實驗結果可知,VSD-YOLOv5s 的 MAP 達到 94.1%,準確率達到 95.1%,相較于另外 3 種模型有所提升,對各類表面缺陷具有良好的檢測效果,識別速度相較于 YOLOv5s,FPS 提高5 fps。因此,與 YOLOv5s,Fast-RC-NN 兩種模型相比,VSD-YOLOv5s 模型具有優越的檢測性能,取得了最佳的檢測效果,能夠滿足在線缺陷檢測系統的較高識別精度需求。
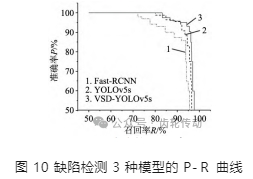
本文將3 種模型在測試過程中產生的準確率以及召回率記錄并繪制 P-R 曲線圖,如圖 10 所示,通過 P-R 曲線我們可以看到 VSD-YOLOv5s 模型的性能優于 Fast-RCNN 和 YOLOv5s。
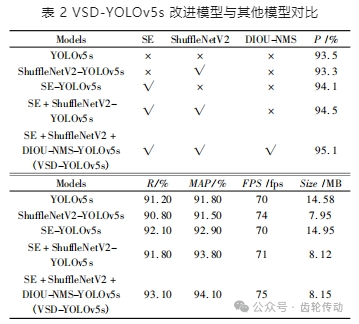
為了驗證不同改進方法對 YOLOv5s 模型性能的影響,本文對多種改進方法進行了比較與討論,如表 2 所示。“√”表明網絡模型中加入此模塊,而“× ”表明網絡模型中沒有加入此模塊。原 YOLOv5s 模型的大小是 14.58 MB,FPS 為 70 fps。使用 ShuffleNetV2 模塊的輕量級 ShuffleNetV2-YOLOv5s 模型的大小減少到 7. 95 MB,FPS 提升到74 fps。結果表明,當在模型中加入 ShuffleNetV2 時,可達到模型輕量化的效果并提升識別速度; 單獨使用 SE 模塊時,YOLOv5s 模型的 MAP 從 91.2% 增加到 92.1% 。ShuffleNetV2-YOLOv5s 模型的 MAP 從 91.80% 增加到93.8% 。當SE 注意力機制、DIOU-NMS 以及 ShuffleNetV2 同時應用時,相比于原模型,VSD-YOLOv5s 模型的識別準確率提升了 0. 9% ,識別精度提升了 1.7% ,識別速度提升了 5 fps, 模型的性能得到了全面改善,達到最優。
四、結論
針對注塑齒輪缺陷檢測存在的問題,提出一種 VSD-YOLOv5s 的齒輪缺陷檢測輕量化網絡模型結構,在改進后的模型架構中,使用了輕量級的 ShuffleNetV2 模塊,為了準確識別注塑齒輪缺陷的不同種類,在模型中引入 SE 注意力機制,將 NMS 改進為 DIOU-NMS 方法加速模型的收斂,在不同測試集進行測試驗證 VSD-YOLOv5s 網絡模型的可行性,實驗結果表明,模型滿足在線檢測系統對高實時性、低漏檢率和低誤檢率的要求,結構更簡化,復雜度更低,檢測識別精度更高。未來在模型的實際應用中,將建立缺陷樣本庫,并及時收集和完善樣本庫,提升檢測效果。
參考文獻略.